이번 영상에서는 Kotlin Flow에 대해 알아보도록 하겠습니다.
¶ Flow란
비동기적으로 작업을 처리하는 코루틴에서 suspend 함수를 사용하면 작업이 모두 완료된 후에 단일 값만을 반환받을 수 있습니다. 하지만 중간중간 진행되는 코루틴 작업중에 갱신되는 값도 반환받을 수 있다면 로직 업데이트를 더 촘촘히 수행할 수 있겠죠.
Flow는 이런 요구를 충족하기 위해 만들어진 타입인데요, suspend 가능한 Iterator라고 하면 이해하기 쉬울 것 같습니다. Flow에서 데이터 스트림에 관여하는 주체는 Producer, Intermediary, Consumer 세 개가 있습니다. Producer가 비동기적으로 값을 생산하면 Intermediary에서는 값을 수정하거나 혹은 그대로 통과시키고, Consumer가 전달받은 값을 소모하게 됩니다.

¶ Flow의 동작
Flow는 빌더를 통해 생성하는데, suspend 키워드를 따로 붙여주지 않아도 블록 내부의 작업이 코루틴에서 수행됩니다. 다음 코드는 100 ms 간격을 두고 1부터 10까지 정수를 방출하는 Flow입니다. 참고로 Flow에서 값을 방출하는데에는 emit, 값을 회수하는데에는 collect 를 사용합니다.
val flow : Flow<Int> = flow {
for (i in 1..10){
delay(100)
emit(i)
}
}
그러면 Kotlin 공식 홈페이지의 예제를 가지고 Flow의 동작에 대해 알아보도록 하겠습니다.
우선 다음과 같은 케이스를 생각해 봅니다. for 내부에서 어떤 계산작업을 수행한다고 하면 그때마다 메인스레드가 100ms동안 멈추게 됩니다.
fun simple(): Sequence<Int> = sequence { // sequence builder
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it
yield(i) // yield next value
}
}
fun main() {
simple().forEach { value -> println(value) }
}
하지만 코루틴을 사용하면 메인스레드의 블록 없이 백그라운드에서 시간이 걸리는 작업을 안전하게 수행할 수 있습니다.
fun main() = runBlocking<Unit> {
simple().forEach { value -> println(value) }
}
suspend fun simple(): List<Int> {
delay(1000) // pretend we are doing something asynchronous here
return listOf(1, 2, 3)
}
그런데 위의 경우에는 작업이 끝난 뒤에 1, 2, 3이 한꺼번에 표시되게 됩니다. 이번엔 Flow를 사용해 보겠습니다. 그러면 백그라운드에서 계산된 결과값 1, 2, 3이 100밀리초마다 순서대로 방출되게 되는데, 이 방출과정은 메인스레드인 launch를 블록하지 않기 때문에 반환값이 다음과 같이 나오게 됩니다.
fun main() = runBlocking<Unit> {
// Launch a concurrent coroutine to check if the main thread is blocked
launch {
for (k in 1..3) {
println("I'm not blocked $k")
delay(100)
}
}
// Collect the flow
simple().collect { value -> println(value) }
}
fun simple(): Flow<Int> = flow { // flow builder
for (i in 1..3) {
delay(100) // pretend we are doing something useful here
emit(i) // emit next value
}
}
// 반환값
I'm not blocked 1
1
I'm not blocked 2
2
I'm not blocked 3
3
¶ Flows are cold
Kotlin에서 Flow는 Cold stream, Channel은 Hot stream으로 정의합니다. Channel에 대한 내용은 여기서 다루지 않겠지만 stream의 차이는 설명하고 넘어가야 할 것 같습니다.
앞에서 보았듯이 Flow는 collect로 값을 요청하지 않는 한 값을 방출하지 않는데 이것을 Cold stream이라고 합니다. 반대로 Hot stream은 요청이 있건 없건 값을 계속 방출하는 방식입니다.
청취자가 듣건 말건 계속 음악을 송신하는 라디오 방송이 Hot stream이라면, 청취자가 직접 CD를 집어넣고 플레이어의 Play 버튼을 눌러야 음악이 시작되는 방식을 Cold stream이라고 할 수 있습니다. 그래서 Hot stream은 청취자가 라디오를 듣기 시작한 시점에 따라 전혀 다른 음악을 듣게 되지만, Cold stream에서는 청취자가 언제 청취를 시작하든 항상 CD의 첫번째 트랙부터 음악을 듣게 됩니다.
다음 예제를 보겠습니다. flow가 만들어졌어도 collect가 수행되기 전까지는 값이 방출되지 않습니다. 또 collect가 수행되면 항상 처음부터 값이 방출되는 Cold stream의 특징을 확인할 수 있습니다.
fun main() = runBlocking<Unit> {
println("Calling simple function...")
val flow = simple()
println("Calling collect...")
flow.collect { value -> println(value) }
println("Calling collect again...")
flow.collect { value -> println(value) }
}
fun simple(): Flow<Int> = flow {
println("Flow started")
for (i in 1..3) {
delay(100)
emit(i)
}
}
// 반환값
Calling simple function...
Calling collect...
Flow started
1
2
3
Calling collect again...
Flow started
1
2
3
¶ Flow vs Livedata
Flow와 Livedata에는 다음과 같은 차이가 있습니다.
-
Flow는 CoroutineScope 안에서 동작하기 때문에 ViewModelScope 나 LifecycleScope와 함께 사용하면
Livedata처럼 ViewModel 또는 Activity/Fragment의 생명주기에 맞춰 동작을 실행 혹은 정지할 수 있습니다. -
딱히 이렇다 할 연산자가 존재하지 않는 Livedata와 비교하면 Flow에는 풍부한 연산자가 있어 데이터를 필요에 따라 유연하게 변환할 수 있습니다.
-
Flow는 Kotlin 언어에 포함된 기능이기 때문에 Livedata 와는 달리 안드로이드 의존성으로부터 자유롭습니다.
정리하면 Livedata는 생명주기를 가진 데이터 홀더로, UI와 연결하면 자동으로 화면을 업데이트 할 수 있다는 명확한 이점이 있습니다. 반면, 메인스레드에서 동작하기 때문에 워커 스레드에서 작업을 처리해야 하는 데이터 레이어에서는 사용하기 적절치 않고, 안드로이드와 밀접하게 결합되어 있기 때문에 테스트가 까다로워진다는 한계가 있습니다.
Flow는 CoroutineScope 안에서 동작하므로 필요에 따라 적당한 스레드를 골라서 사용할 수 있습니다. 안드로이드의 라이프사이클을 감지할 수 있고, 안드로이드 의존성도 제거할 수 있습니다. 다만 Cold stream이기 때문에 collect 되어야만 값을 방출하며, 상태가 없으므로 .value의 형태로 현재 값을 얻을 수 없다는 한계가 있습니다.
¶ Sharedflow로 Livedata 대체하기
그런 흐름에서 발표된 것이 SharedFlow와 StateFlow입니다. SharedFlow는 Hot stream으로 동작하게 구성된 Flow의 한 종류인데요, 여기에 상태를 부여하여 현재 값을 얻을 수 있게 제한을 가한 것이 StateFlow입니다. LiveData와 비슷한 동작을 하면서도 UI~데이터 레벨까지 사용할 수 있는 데이터 홀더라고 보시면 됩니다. 이러한 이유들로 구글은 UI를 표시하는 데이터 홀더를 Livedata에서 StateFlow 로 변경하고 있는 추세입니다.
Flow는 stateIn 함수를 사용해 다음과 같이 StateFlow로 변환할 수 있습니다. 이 때 scope는 StateFlow가 작동할 스코프, started는 구독을 시작하는 타이밍, initialValue는 초기값을 의미합니다.
fun <T> Flow<T>.stateIn(scope: CoroutineScope, started: SharingStarted, initialValue: T): StateFlow<T>
SharingStarted에는 다음과 같은 세 가지 옵션이 있습니다.
-
SharingStarted.Eagerly: collector가 존재하지 않더라도 바로 sharing이 시작되며 중간에 중지되지 않음.
-
SharingStarted.Lazily: collector가 등록된 이후부터 sharing이 시작되며 중간에 중지되지 않음.
-
SharingStarted.WhileSubscribed: collector가 등록되면 바로 sharing을 시작하며 collector가 전부 없어지면 바로 중지됨.
구글에서는 started를 WhileSubscribed(5000)으로 설정하는 것을 권장하고 있는데요, 그 이유는 Flow의 중단 타이밍과 관련됩니다.
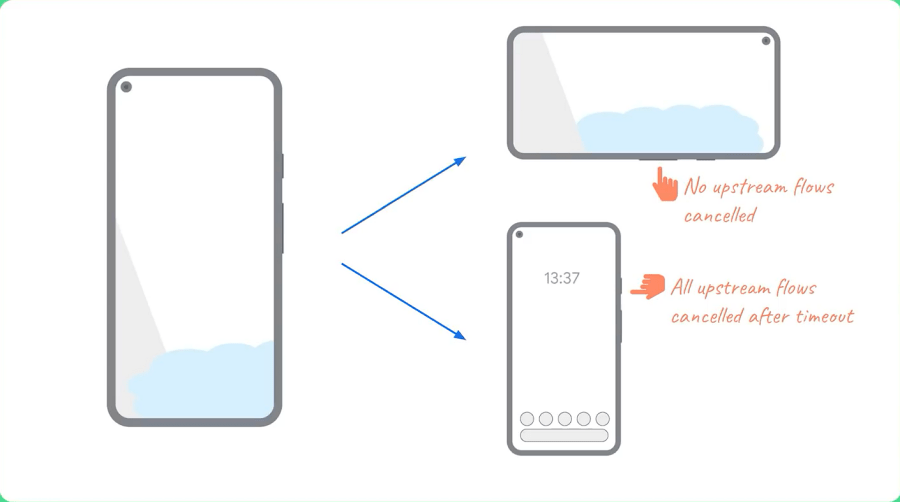
예를 들어 액티비티가 파괴되었다가 바로 재생성되는 경우와, 앱이 백그라운드로 전환되는 두 가지 상황을 생각해봅시다. 두번째 상황에서는 리소스 절약을 위해 모든 Flow가 중지되어야 하지만, 첫번째 상황은 데이터를 바로 다시 사용해야 하기 때문에 Flow를 재시작해서는 안됩니다. 이 두 상황을 구분하는데 WhileSubscribed(5000)이 사용됩니다.
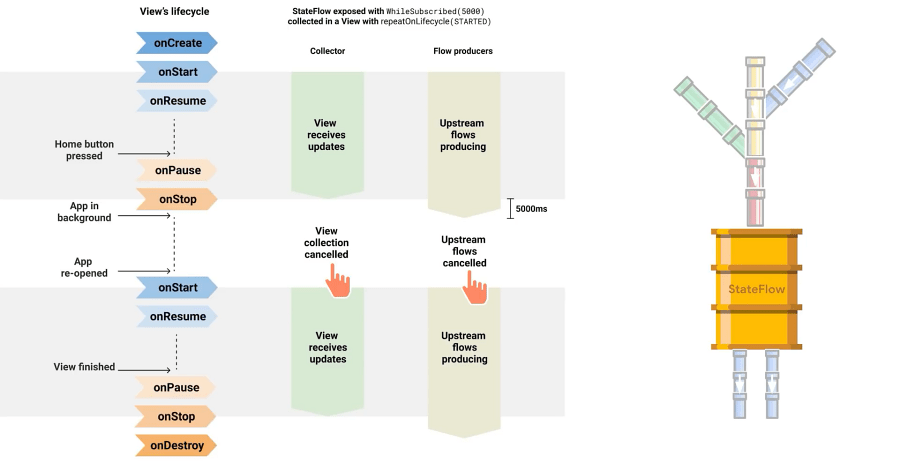
두 상황 모두 일단 flow 수집이 중단됩니다. 그런데 액티비티 재생성의 경우엔 바로 데이터를 다시 수집하게 되지만 백그라운드로 넘어간 경우 수집은 그대로 멈추게 됩니다. 따라서 데이터를 다시 수집하는데 걸리는 딜레이를 5초로 주면 이 두 상황을 구분하여 Flow의 정지 여부를 결정할 수 있게 된다는 것입니다.
이렇게 해서 Kotlin flow에 대해 알아보았습니다.